Experiment
Experiments are attempts to reach a specific objective based on a hypothesis by using a pipeline. They are used to test your pipelines and train machine learning models before scheduling them with a Trigger.
Running a pipeline
Using the Pipeline UI, open your pipeline from AI Lab > Build > Pipelines and click the Execute button at the top right of the Pipeline Editor. A dialog will open where you can configure the execution with the following options:
- Experiment: link the execution to an existing experiment or leave it empty to generate a new one.
- Twin Unit: select the twin unit to run the pipeline against.
- Now: override the reference datetime to simulate an execution at a different point in time.
- Version: select the Python version to use. If not specified, the platform default will be used.
- Train: toggle whether the pipeline should train the machine learning model(s).
- Plot: toggle whether the pipeline should execute the plot step(s).
- Write: toggle whether the pipeline should write results back to the time-series database. This is disabled by default in experiment mode.
- Variables: Fill any variables required by the pipeline, they will be merged with properties.
- Properties: Define a JSON dictionary to send extra information inside the execution properties.
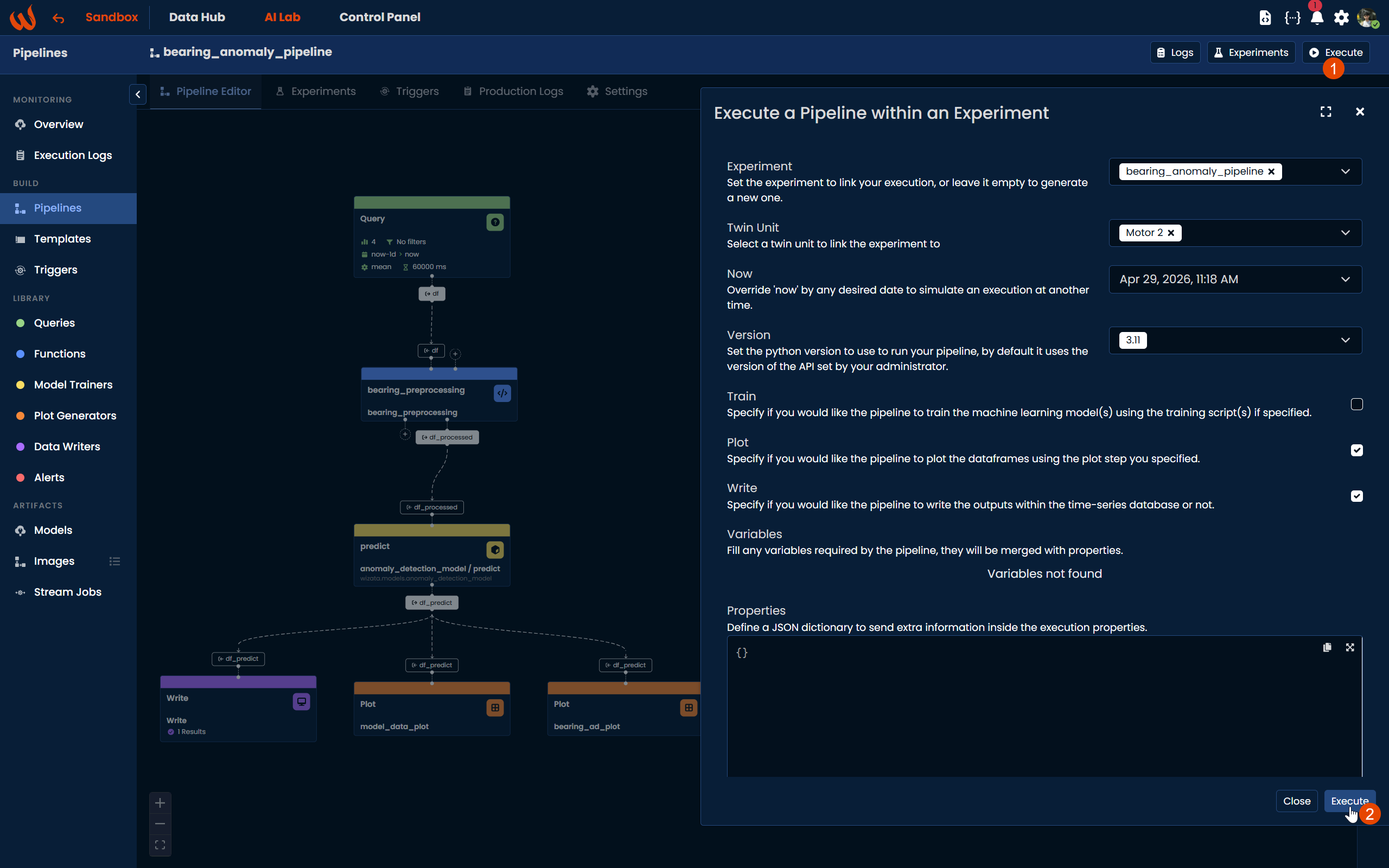
Once configured, click Execute to run.
Using the Python Toolkit, run a pipeline in experiment mode as follows:
execution = wizata_dsapi.api().experiment(
experiment='my_experiment',
pipeline='my_pipeline',
twin='my_twin'
)To link your execution to a named experiment for tracking purposes, create or update the experiment first:
wizata_dsapi.api().upsert_experiment(
key='my_experiment_key',
name='My Experiment Display Name',
pipeline='my_pipeline_key'
)Twin
The Twin must be referenced using its hardware ID as registered on the template used by the pipeline.
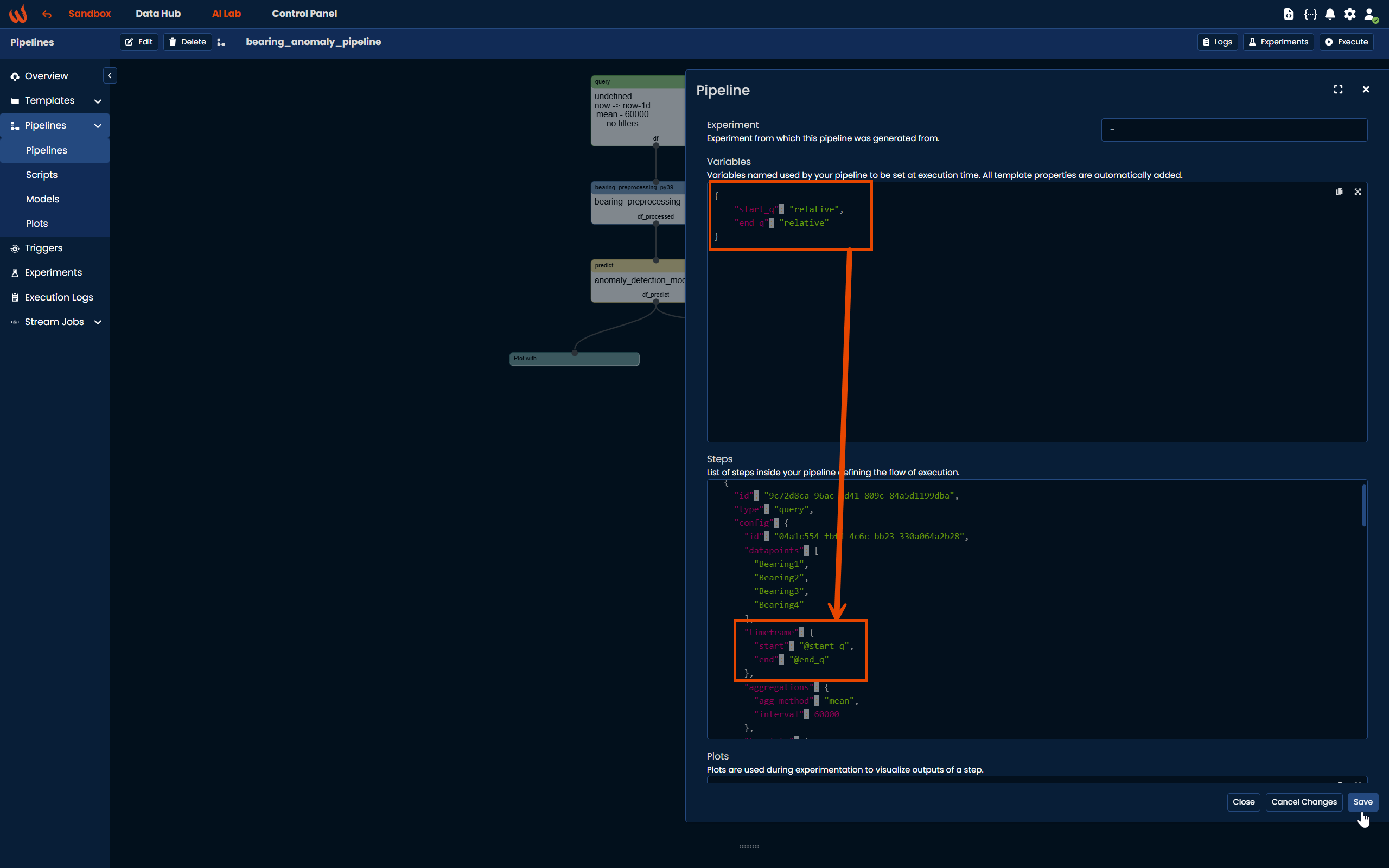
Properties
Properties can refer to any parameter within your pipeline using the @var_name notation, or simply a value you would like to use within your scripts. A variable does not need to be declared on a pipeline to be used, but note that it will not be available to specify from the UI unless it is declared.
For example, you can define the relative variables start_q and end_q to dynamically control the time range of your Query step:
When executing from the UI, you can define a JSON dictionary to send extra information inside the execution properties directly from the Execute dialog:
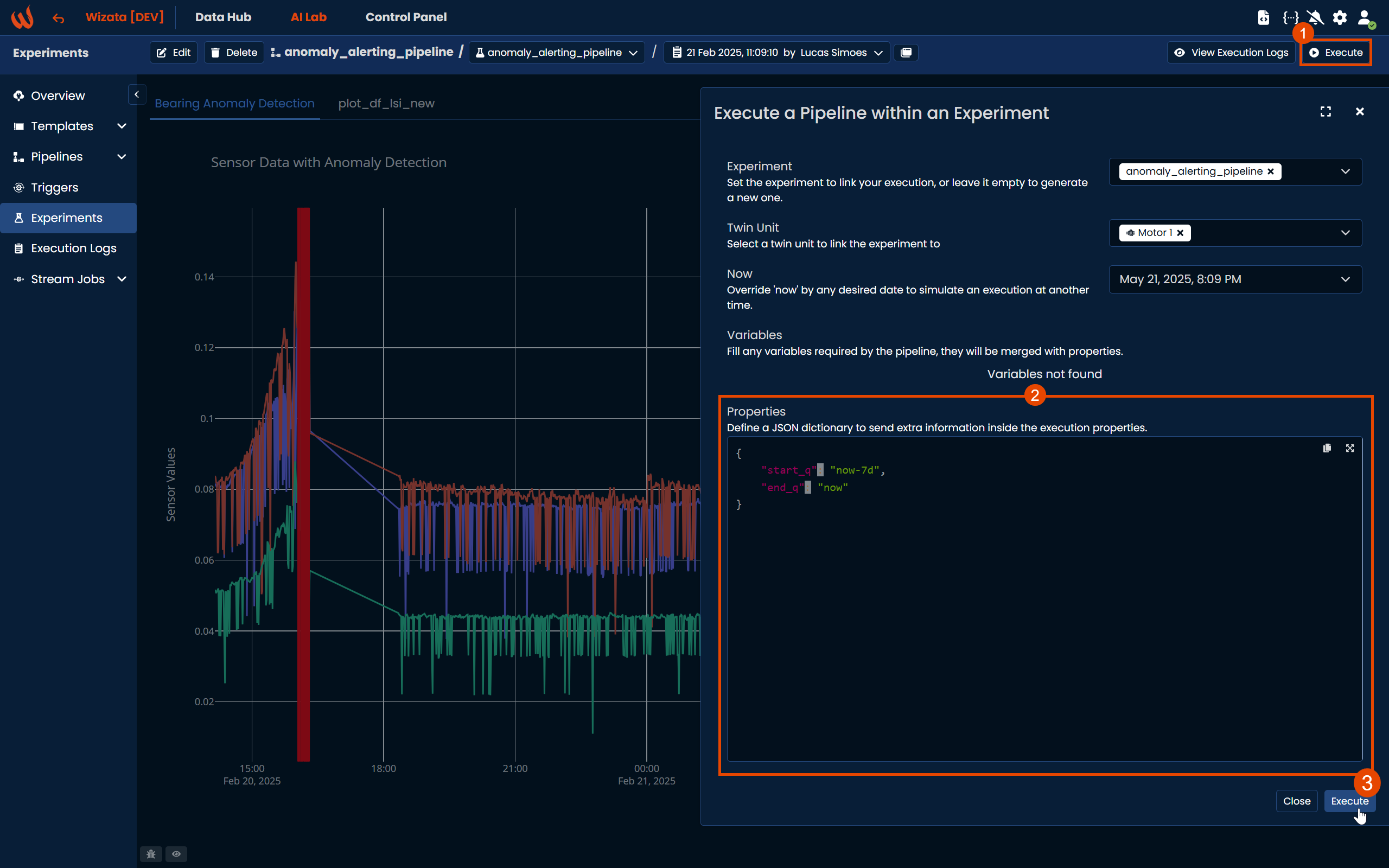
Alternatively, you can pass the properties dictionary programmatically when executing the experiment via Python:
execution = wizata_dsapi.api().experiment(
experiment='my_experiment',
pipeline='my_pipeline',
twin='my_twin',
properties={
'start_q': 'now-7d',
'end_q': 'now'
}
)Options
In experiment mode, by default ML model are trained and scored, plots steps are executed, but no data are written back to the platform. You can override this behavior using execution_options:
execution = wizata_dsapi.api().experiment(
experiment='my_experiment',
pipeline='my_pipeline',
twin='my_twin',
properties={
'start_q': 'now-7d',
'end_q': 'now'
},
train=False,
plot=False,
write=True
){
"properties" : {
"execution_options" : {
"train" : false,
"plot" : false,
"write" : true
}
}
}Pipeline Images
You can also pass a pipeline image key when running an experiment, which will use the packaged version of the pipeline instead of the live definition:
wizata_dsapi.api().experiment(
experiment='my_experiment_key',
pipeline='my_pipeline_key',
twin='my_twin_name',
image='my_pipeline_image_key'
)For more details on building and managing pipeline images, refer to the Pipeline Images article.
Python version
When executing an experiment from the UI, you can select the Python environment to use. If not specified, the platform default version will be applied.
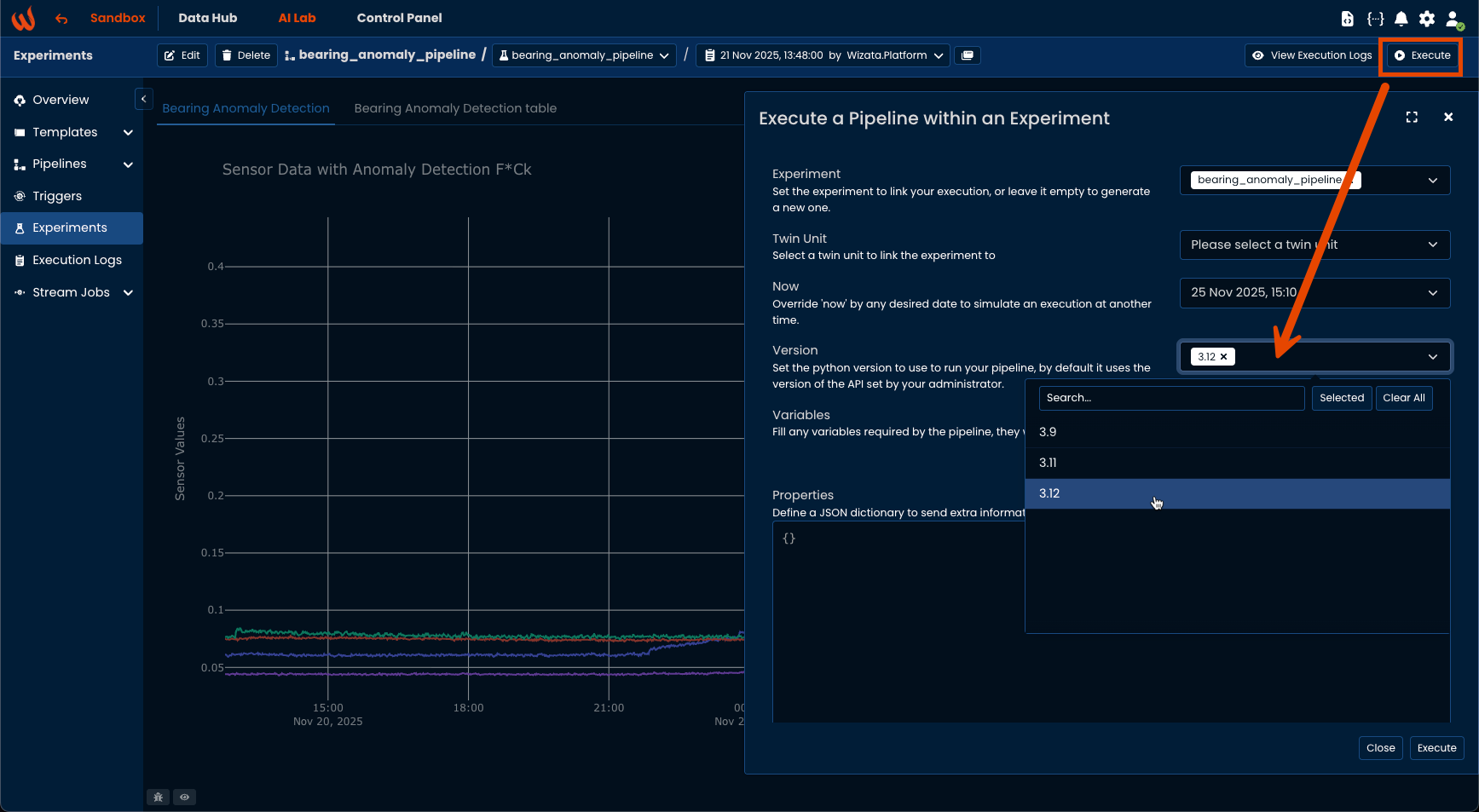
When using the experiment() method from Python, your local version is automatically sent to the platform as the desired version. You can also set it manually:
execution = wizata_dsapi.api().experiment(
experiment='my_experiment',
pipeline='my_pipeline',
twin='my_twin',
version='3.12'
)To check which versions are available in your platform, navigate to AI Lab > Overview
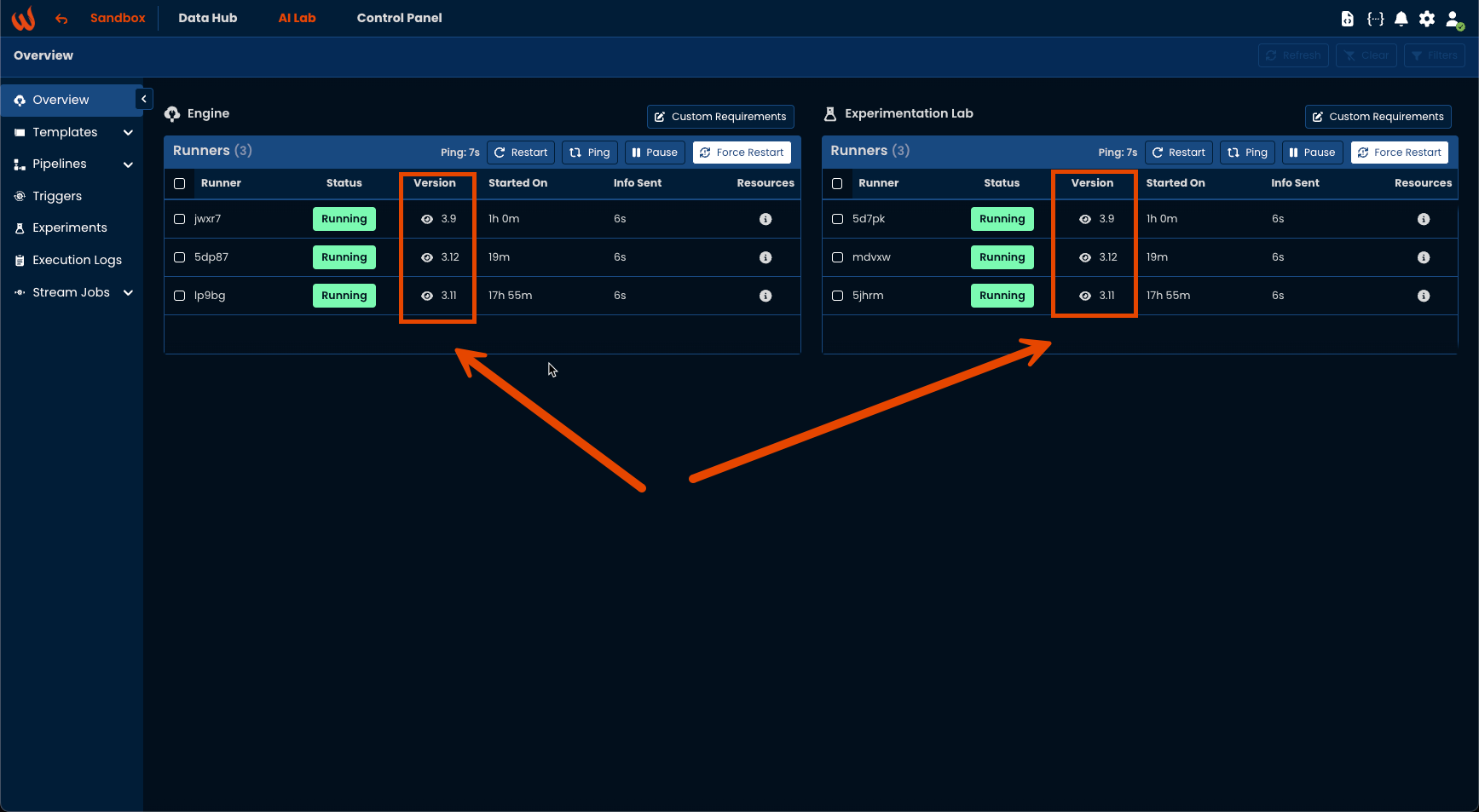
For more information, you can take a look at the dedicated article on Upgrading your solution Python version
Viewing Experiment Results
Once an experiment has been executed, you can review the results in the Experiments tab of your pipeline. Click the eye icon next to a completed execution to open the detail panel, where all generated plots and output tables are displayed.
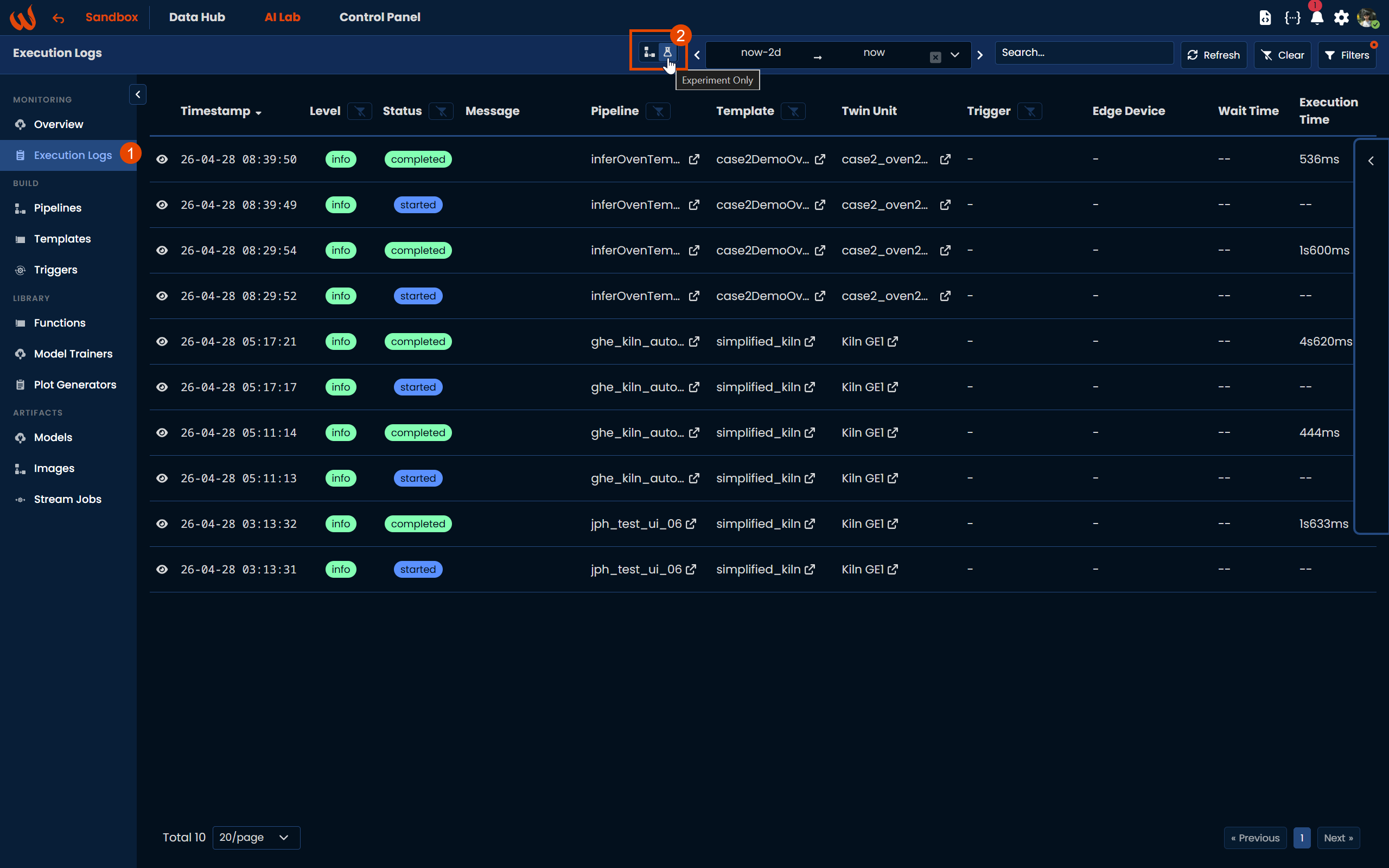
To review the execution logs, navigate to AI Lab > Execution Logs. From there you can filter by experiments only using the dedicated filter button, which makes it easier to isolate experiment runs from production executions.
Deleting an experiment
To delete an experiment from Python, use the .get() method to retrieve it and then pass it to .delete():
experiment_object = wizata_dsapi.api().get(experiment_key="pipeline_dev5352")
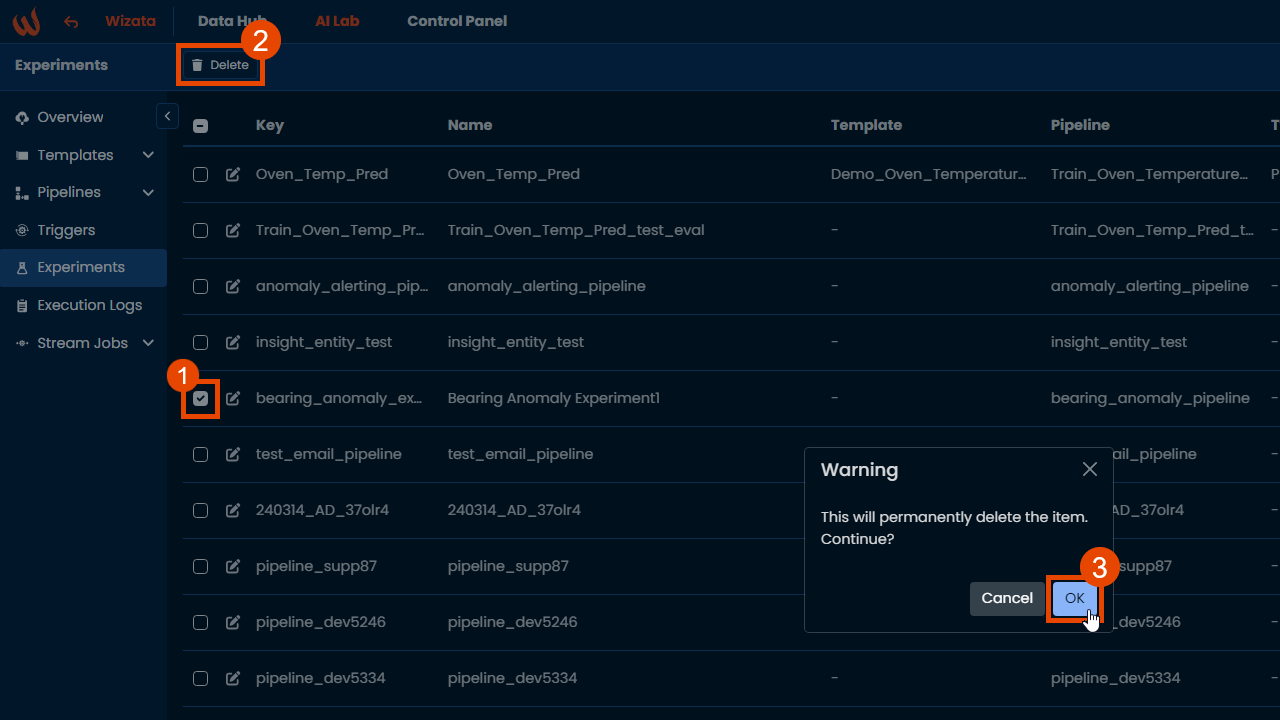
wizata_dsapi.api().delete(experiment_object)From the UI, navigate to the Experiments page inside the AI Lab section and use the delete option from there.
Updated 3 months ago