Script step
A Script step executes a custom Python function within the pipeline. Scripts can be used for a wide range of tasks including data transformations, Plotly visualizations, connectivity with third-party services, and machine learning model training. They allow you to share reusable logic with your team to be used across different pipelines in Wizata.
The custom script must have the same number of Data Frames inputs and outputs as declared in the step. You can always add a properties dict or a context object as a parameter to access additional execution information.
Script Types
Scripts in Wizata can be of three types:
- Embedded: scripts created directly from the platform through Library > Functions. These are stored and managed within Wizata and are the most common type when building solutions from the UI.
- Uploaded: scripts uploaded programmatically using the Python SDK. These are typically developed locally and pushed to the platform using
wizata_dsapi.api().upsert(). - Built-in: scripts provided by the Wizata library, available out of the box for common use cases such as anomaly detection or regression. For more details, refer to the Wizata library for common functions.
Creating a Script
Using the Pipeline UI, navigate to Library > Functions and click + Create new script to write a new script directly from the platform. Once saved, it will appear in the Functions list as an Embedded script, ready to be used in any pipeline.
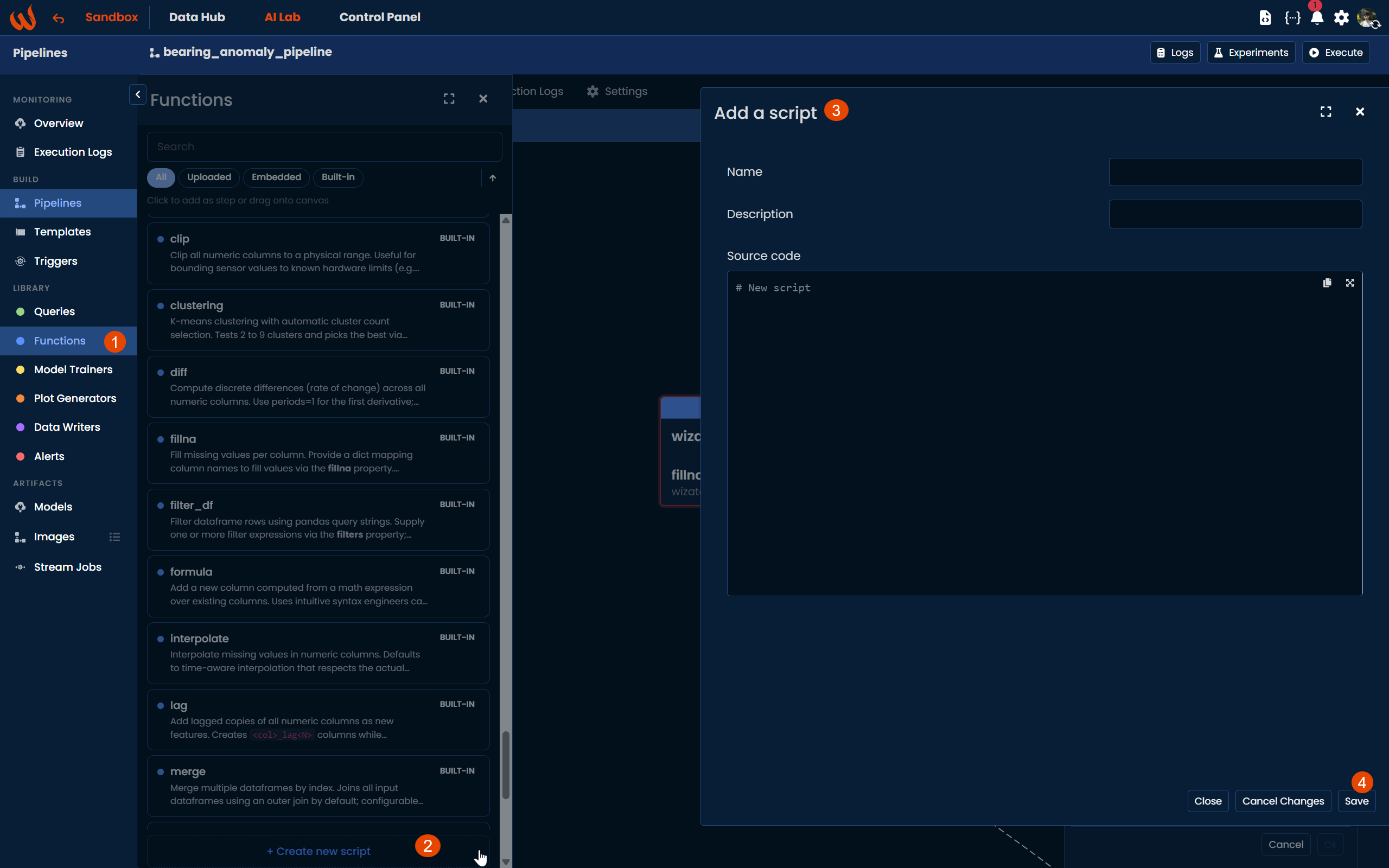
Script Fields
When creating a script, there are three fields worth understanding beyond the function code itself.
Category
The category determines in which type of pipeline step the script will be available:
- Function: for data transformation scripts. These appear under Library > Functions and can be used in a Script step.
- Model: for machine learning training scripts. These appear under Library > Model Trainers and can be used in a Model step.
- Plot: for visualization scripts. These appear under Library > Plot Generators and can be used in a Plot step.
Scripts created without a category are treated as Function by default.
Description
A free-text field that accepts markdown. It is displayed in the Library panel when browsing scripts. The recommended format follows the same convention used by the built-in Wizata library:
Short one or two line summary of what the script does.
### Properties
* **property_name** _(type)_ — description of what it doesProperties
A declarative schema that maps property names to their expected types. The supported types are str, int, float, bool, list, and dict. When defined, the UI reads this schema to automatically generate a configuration form for the step, making it easier for users to fill in the required parameters without having to read the script source. Using the Python Toolkit, these fields can be set when registering a script:
def my_transformation(context):
threshold = context.properties.get("threshold", 0.05)
window = context.properties.get("window", 60)
df = context.dataframe
# YOUR LOGIC
return df
script = wizata_dsapi.Script(
function=my_transformation,
category=wizata_dsapi.ScriptCategory.FUNCTION,
description="Filter and smooth dataframe values.\n\n### Properties\n- **threshold** *(float)* — minimum value to keep\n- **window** *(int)* — smoothing window in seconds",
properties={
"threshold": "float",
"window": "int"
}
)
wizata_dsapi.api().upsert(script)Using the Python Toolkit to register the script without the additional fields, you can also continue using the simpler form:
wizata_dsapi.api().upsert(your_function)If you are unsure whether your function name is unique, use the get function to check. If the function does not exist, you will receive a 500 not found exception.
my_script = wizata_dsapi.api().get(
script_name="function"
)
print(my_script)You can alternatively use the create and update functions to have explicit control over the operation being executed.
wizata_dsapi.api().create(
wizata_dsapi.Script(
function=<function>
)
)
wizata_dsapi.api().update(
wizata_dsapi.Script(
function=<function>
)
)Adding a Script step to the Pipeline
Using the Pipeline UI, navigate to Library > Functions in the left-hand panel. You can filter by Embedded, Uploaded, or Built-in scripts. Drag the desired script onto the canvas or click + Create new script to write a new one directly from the platform. Once the block is on the canvas, open the configuration panel on the right to connect inputs and outputs using named dataframe blocks.
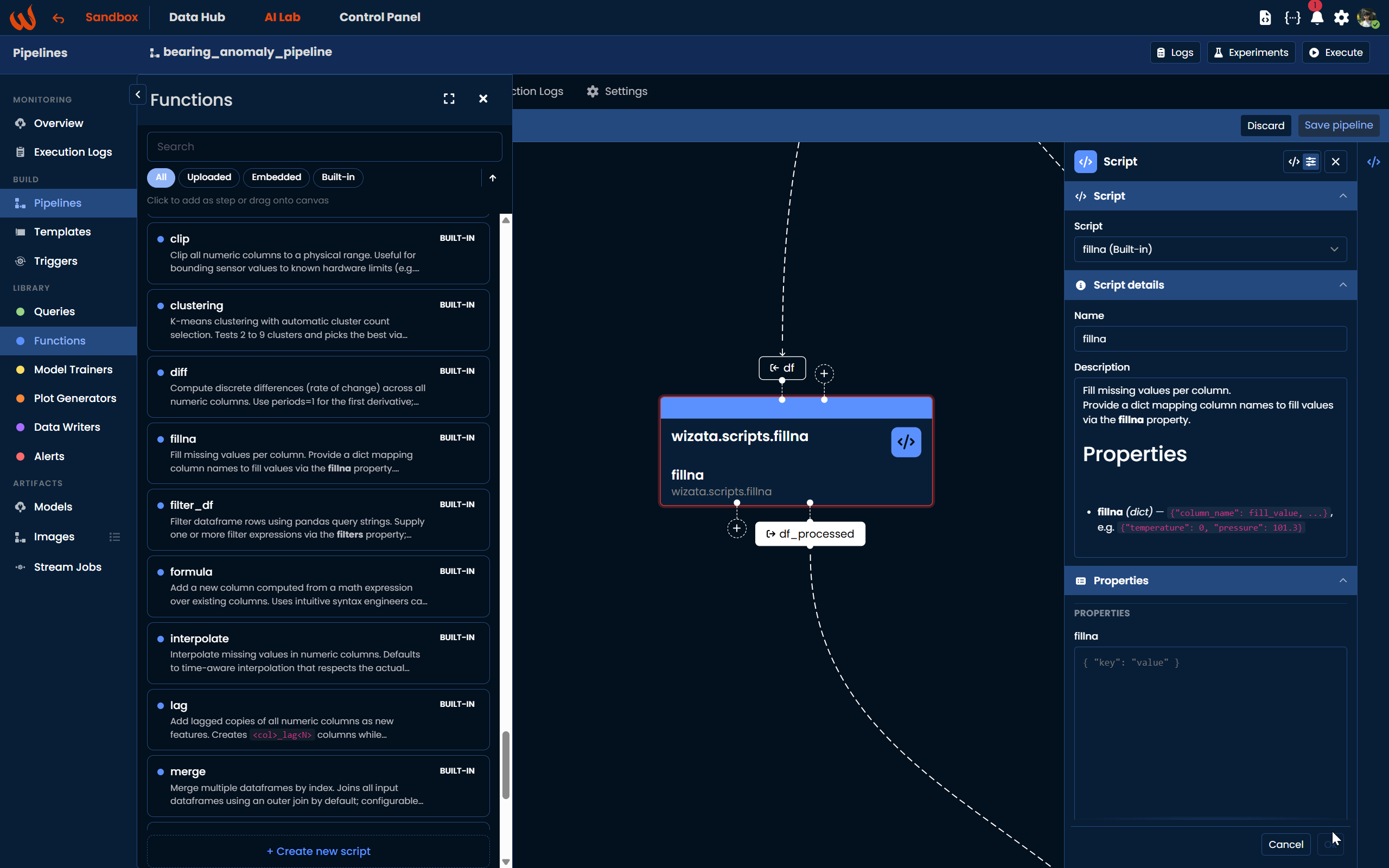
Using the Python Toolkit, once your script is registered on the platform you can add it as a step in the pipeline using pipeline.add_transformation():
pipeline.add_transformation(
script="your_function_name",
input_df_names=['query_output'],
output_df_names=['transformed_data']
)The key parameters are:
script: the name of the function registered on the platform.input_df_names: the list of named input dataframes coming from previous steps.output_df_names: the list of named output dataframes to be passed to subsequent steps.
Step Name and Description
Once a script block is on the canvas, you can assign it a custom name and description directly on the step, independently of the script itself. This is useful when the same script is reused in multiple places within a pipeline and you want to label each step with a more descriptive context, for example "Outlier removal - Plant 3" instead of the generic script name.
Parameters
Depending on your needs, you can bind different types of parameters to your script function. Your function must accept at least one parameter to be compatible with Wizata. Parameters are bound based on their type annotation first, and then by their variable name.
To access all available data within your function, use a Context object via the type annotation wizata_dsapi.Context or by naming your parameter context:
def your_function(context: wizata_dsapi.Context):
df = context.dataframe
props = context.propertiesWithin the context, you can also access all properties from datapoints used in queries through context.datapoints. This is a dictionary where the key is either the hardware ID or the template property name used in the request.
You can check all the possible uses for context on the SDK Context reference article
Properties
Context may useful custom variables and configuration information through the properties dictionary, accessible via context.properties.
def your_function(context: wizata_dsapi.Context):
props = context.propertiesAlways check for missing keys or NoneType to prevent runtime errors.
def your_function(context: wizata_dsapi.Context):
if context.properties['mykey'] is None:
raise KeyError('cannot find mykey within properties in your_function')You can also use type annotation dict or the name props or properties as alternatives.
def sample1(properties):
return
def sample2(params: dict):
return
def sample3(props):
returnThe order of parameters has no importance. Binding is resolved first by type annotation, then by parameter name.
Dataframes
Data Frames are the primary data structure passed between steps. They allow you to create transformation scripts or process the output of a query or another step.
def transformation(context: wizata_dsapi.Context):
df = context.dataframe
# YOUR LOGIC
context.result_dataframe = dfYou can simplify the declaration using type annotation or the parameter names df or dataframe:
def transformation(df: pandas.DataFrame) -> pandas.DataFrame:
# YOUR LOGIC
return dfYou can also work with multiple inputs and outputs:
def transformation(df1: pandas.DataFrame, df2: pandas.DataFrame):
# YOUR LOGIC
return df3, df4Always use type annotations to avoid incorrect parameter binding.
JSON Format of the Script step
Here is an example of a script step config using a split function:
{
"type": "script",
"config": {
"function" : "split_df"
}
"inputs": [
{ "dataframe" : "query_output" }
],
"outputs": [
{ "dataframe" : "first_output" },
{ "dataframe" : "second_output" }
]
}The Script step must contain the following properties :
configwith afunctionkey referring to your script name.inputswith a list of input dataframe names.outputswith a list of output dataframe names.
A script must have at least one output or one input.
Features Mapping
Features mapping renames columns in the input dataframe before passing them to your script. The key is the name your script expects and the value is the actual column name found in the dataframe.
{
"type": "script",
"config": {
"function" : "split_df",
"features_mapping" : {
"feature_column" : "query_column"
}
},
"inputs": [
{ "dataframe" : "query_output" }
],
"outputs": [
{ "dataframe" : "first_output" },
{ "dataframe" : "second_output" }
]
}Properties Mapping
Properties mapping renames properties in the context before passing them to your script. The key is the name your script expects and the value is the actual property name found in the context.
{
"type": "script",
"config": {
"function" : "split_df",
"properties_mapping" : {
"percentage" : "pct",
"size" : "amount"
}
},
"inputs": [
{ "dataframe" : "query_output" }
],
"outputs": [
{ "dataframe" : "first_output" },
{ "dataframe" : "second_output" }
]
}Both mappings are reversed after your script executes, leaving the dataframe and properties as they were received, except for any modifications your script applied to them.
If you mention a feature or a property in the mapping, it becomes mandatory.
Data Points
Within a script step you can access Data Point properties and other useful information through the context object. Use context.datapoints[name_of_your_datapoint] to retrieve the corresponding wizata_dsapi.DataPoint object.
Updated 2 months ago