Multi-bucket support on queries
As explained in our article on buckets, InfluxDB 2.x and above supports the use of multiple buckets. While the default bucket configured in the system is used automatically, there are several ways to query data from other buckets.
Data Stores
Starting version 11.1, Data stores allow you to organize time-series data in separate containers, making it easier to manage operations like backup, migration, restore and deletion.
For more information, refer to our dedicated article.
If your datapoint is already linked to the correct data store, you can normally query your data without having to specify abucket parameter inside it.
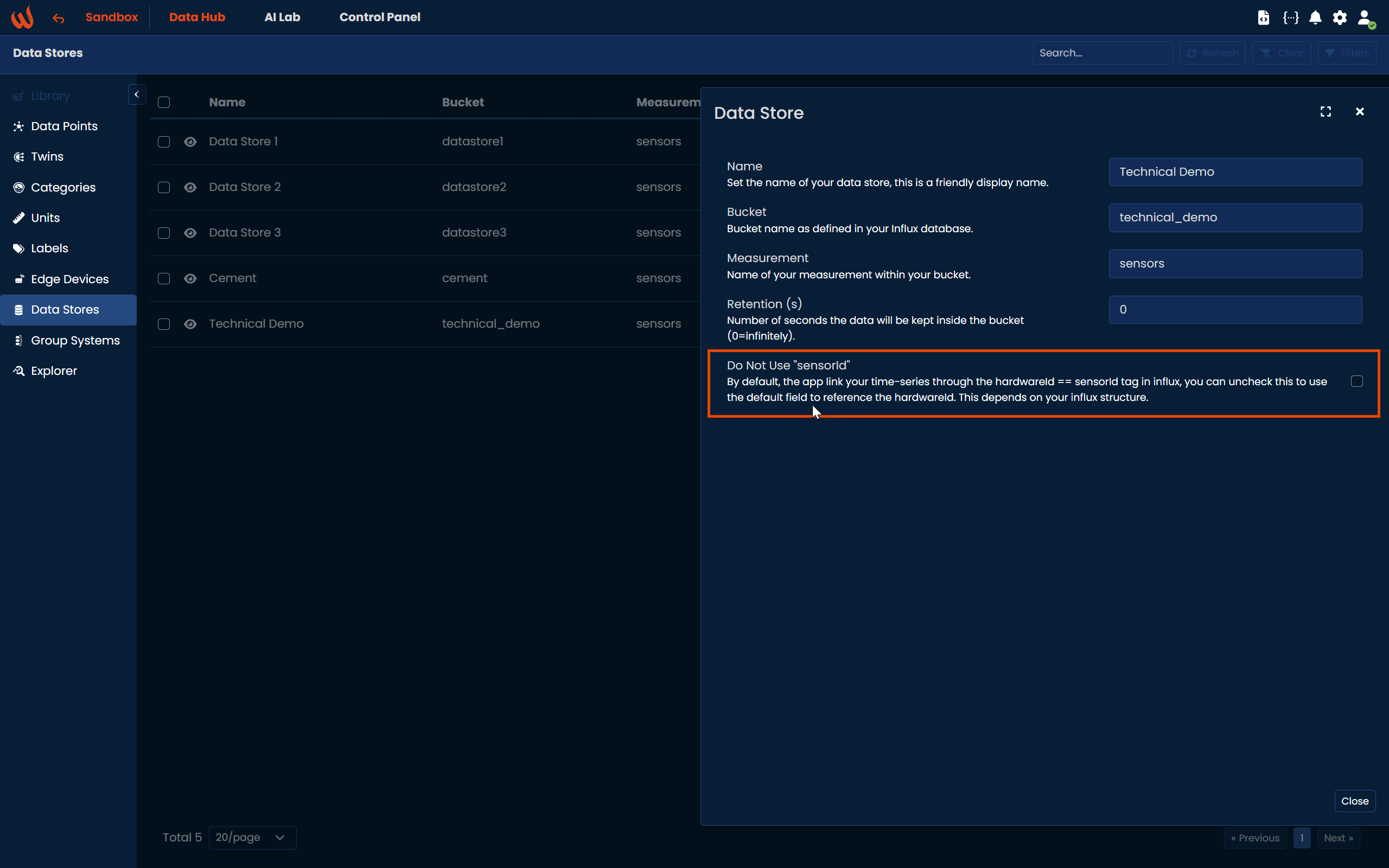
"Do Not Use sensorId" option
sensorId" optionWhen creating a new Data Store entity, you will encounter a doNotUserSensorId checkbox.
By default, the system links time-series data through the tag sensorId, which must match the datapoint’s hardwareId.
If you uncheck this option, the platform will instead use the default field-based mapping to match the hardwareId.
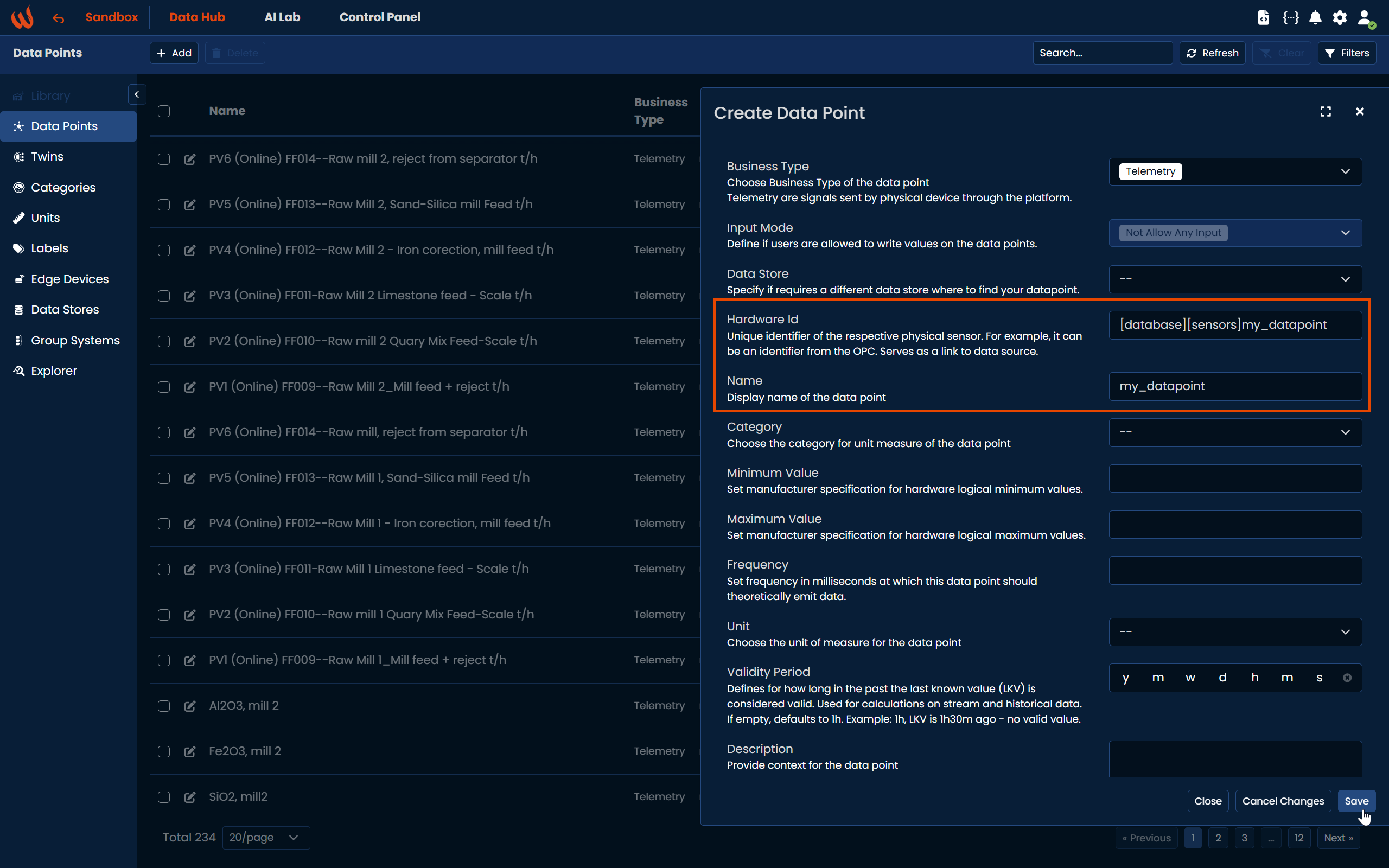
Extra tags in datapoints
As an alternative, you can also specify the bucket and measurement directly in the datapoint’s hardwareId
This is useful when querying data stored in a non-default bucket or measurement.
To do this, format the hardware ID as [bucket][measurement]my_datapoint
For example, if your data is stored in bucket database and measurement sensors, the hardwareId should be [database][sensors]my_datapoint
Updated 9 months ago