Write step
A Write step is used to write data back into the time-series database. It maps columns from an output dataframe to registered datapoints in the platform, storing the results at the timestamps provided by the dataframe index. Write steps should be used carefully as they modify data within the time-series database. For this reason, they are deactivated by default during experiment mode.
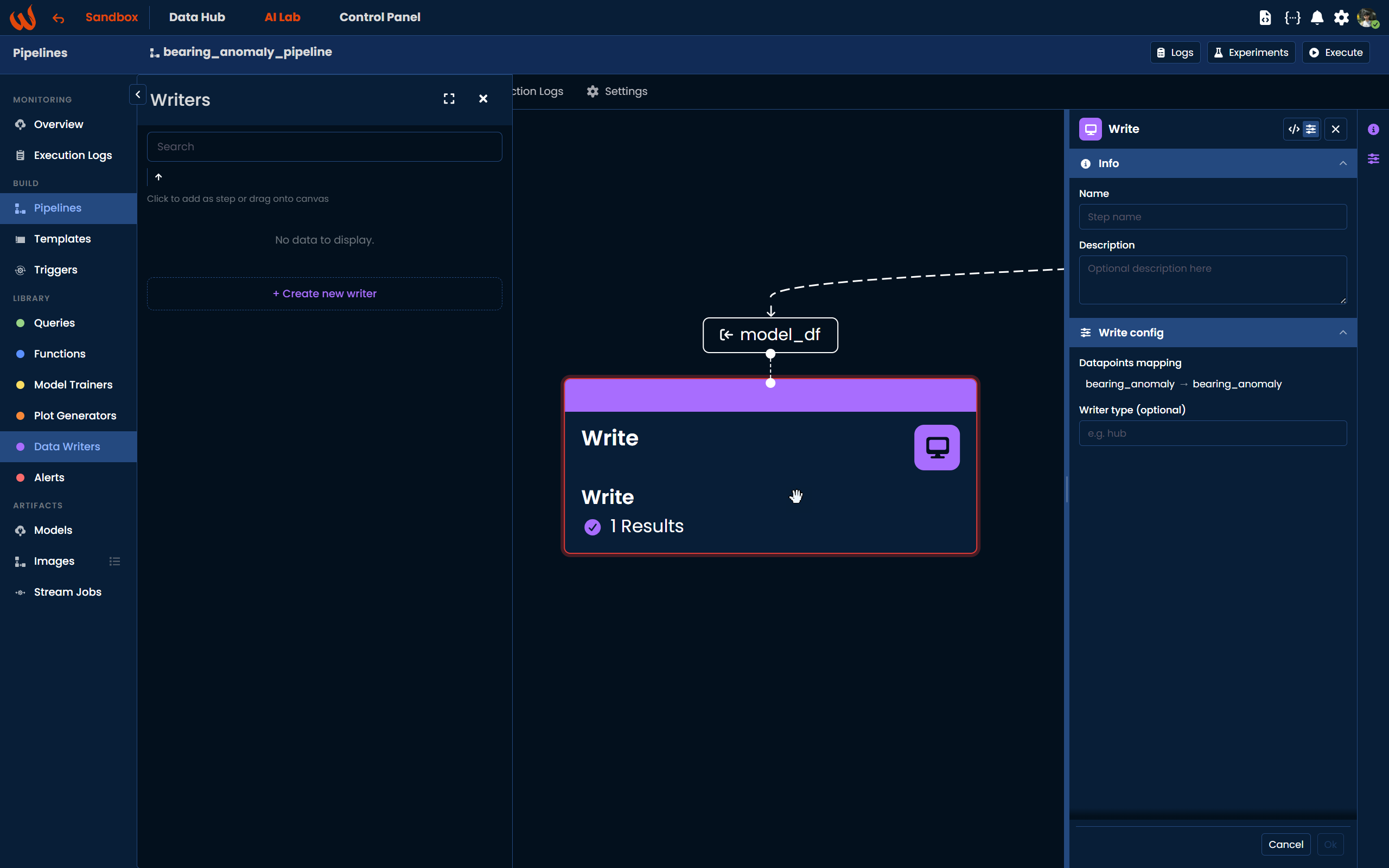
Adding a Write Step
Using the Pipeline UI, navigate to Library > Data Writers in the left-hand panel and drag the block onto the canvas. Once added, open the configuration panel on the right to define the mapping between your dataframe columns and the target datapoints. When done, click Ok to confirm.
Using the Python Toolkit, add the write step to the pipeline using pipeline.add_writer() with a WriteConfig object:
pipeline.add_writer(
config=wizata_dsapi.WriteConfig(
datapoints={
"bearing_anomaly": "bearing_anomaly"
}
),
input_df='df_predict'
)For the full list of available parameters, refer to the WriteConfig reference.
Datapoint Mapping
The Write step config requires a mapping between dataframe columns and target datapoints. Each entry in the mapping follows one of these formats:
"df_column" : "datapoint_hardware_id": maps directly to a specific datapoint using its hardware ID."df_column" : "template_property": maps using a template property name, which is resolved to the actual datapoint for each twin at execution time. This is the recommended approach when using templates.
Here is an example using template property names:
{
"type": "write",
"config": {
"datapoints": {
"sum_all_columns": "bearing_output"
}
},
"inputs": [
{ "dataframe": "sum_dataframe" }
]
}If you need to manipulate the writing timestamp, for example when writing forecasted values, combine the Write step with a Script step and relative date variables to adjust the dataframe index before writing.
Dynamic Mapping
In some cases the mapping between dataframe columns and datapoint hardware IDs cannot be defined statically and needs to be resolved at runtime. For this, you can use the map_property_name config key, pointing to a property name that contains the mapping dictionary.
{
"type": "write",
"config": {
"map_property_name": "your_property_name"
},
"inputs": [
{ "dataframe": "sum_dataframe" }
]
}The property referenced by map_property_name must contain a dictionary where the keys are dataframe column names and the values are datapoint hardware IDs. This property can be passed directly when calling the pipeline or set dynamically by a previous Script step.
As a reminder, properties are shared across all pipeline steps as a dictionary, initialized at execution time and accessible via
context.properties[key].
Updated 3 months ago