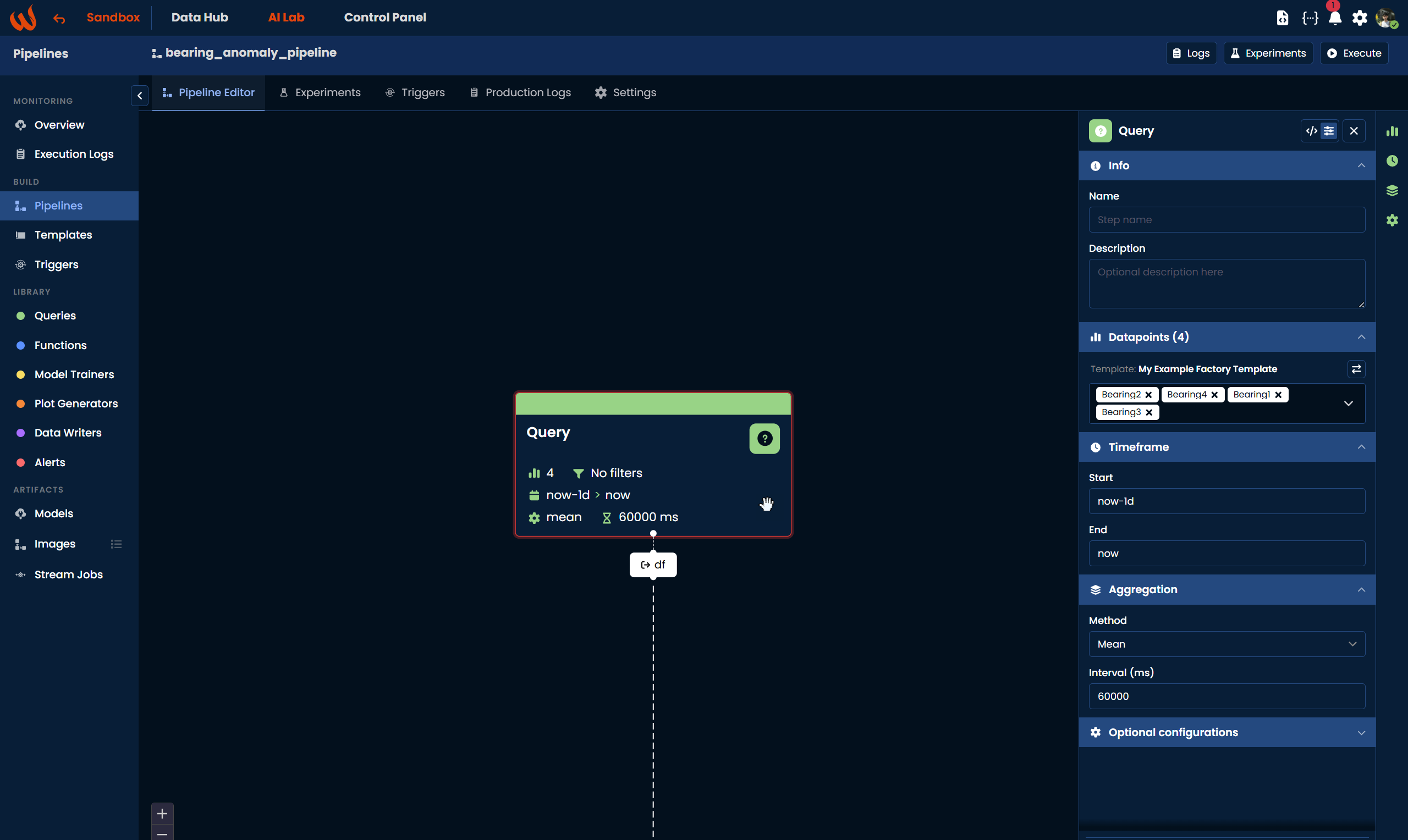
Query step
A query step is used to fetch time-series data from the platform and produce an output Data Frame, that can be used by the subsequent steps in the pipeline. A Query step has only one output and no inputs, meaning it always acts as the starting point of a pipeline.
The query configuration is identical to the Data Hub Query and can be defined either as a wizata_dsapi.Request object or its equivalent JSON form.
Adding a Query step
Using the Pipeline UI, navigate to Library > Queries in the left-hand panel and either drag the block onto the canvas or click + Create new query. Once the block is added, a configuration panel opens on the right where you can set the datapoints, timeframe, aggregation method, and interval. When done, click Ok to confirm.
Using the Python Toolkit, add a query step to the pipeline using pipeline.add_query():
pipeline.add_query(
wizata_dsapi.Request(
datapoints=["Bearing1", "Bearing2", "Bearing3", "Bearing4"],
start="now-1d",
end="now",
agg_method="mean",
interval=60000
),
df_name="query_output"
)The key parameters are:
datapoints: the list of datapoints or template property names to query.start / end: the time window to retrieve. Accepts fixed datetimes, epoch timestamps, or relative expressions likenow-1d.agg_method: the aggregation method applied within each interval. Common options aremean,min,max, andsum.interval: the aggregation interval in milliseconds. For example,60000produces one data point per minute.df_name: the name assigned to the output dataframe, used to reference it in subsequent steps.
pipelinebeing the pipeline object already defined. For the full list of available parameters, refer to the SDK Request reference.
Define the Timeframe
The timeframe of a query can be defined in three ways:
- Fixed: using an explicit
start/endas a datetime or epoch timestamp. - Relative: using
now-based expressions likenow-1hornow-7d. By default,nowis set to the moment the pipeline was queued. - Variable: using a custom
@variablethat can be overridden by the user at execution time or set automatically by a Trigger.
For more details on query options, filters, and advanced configurations, refer to the Query article.
Output
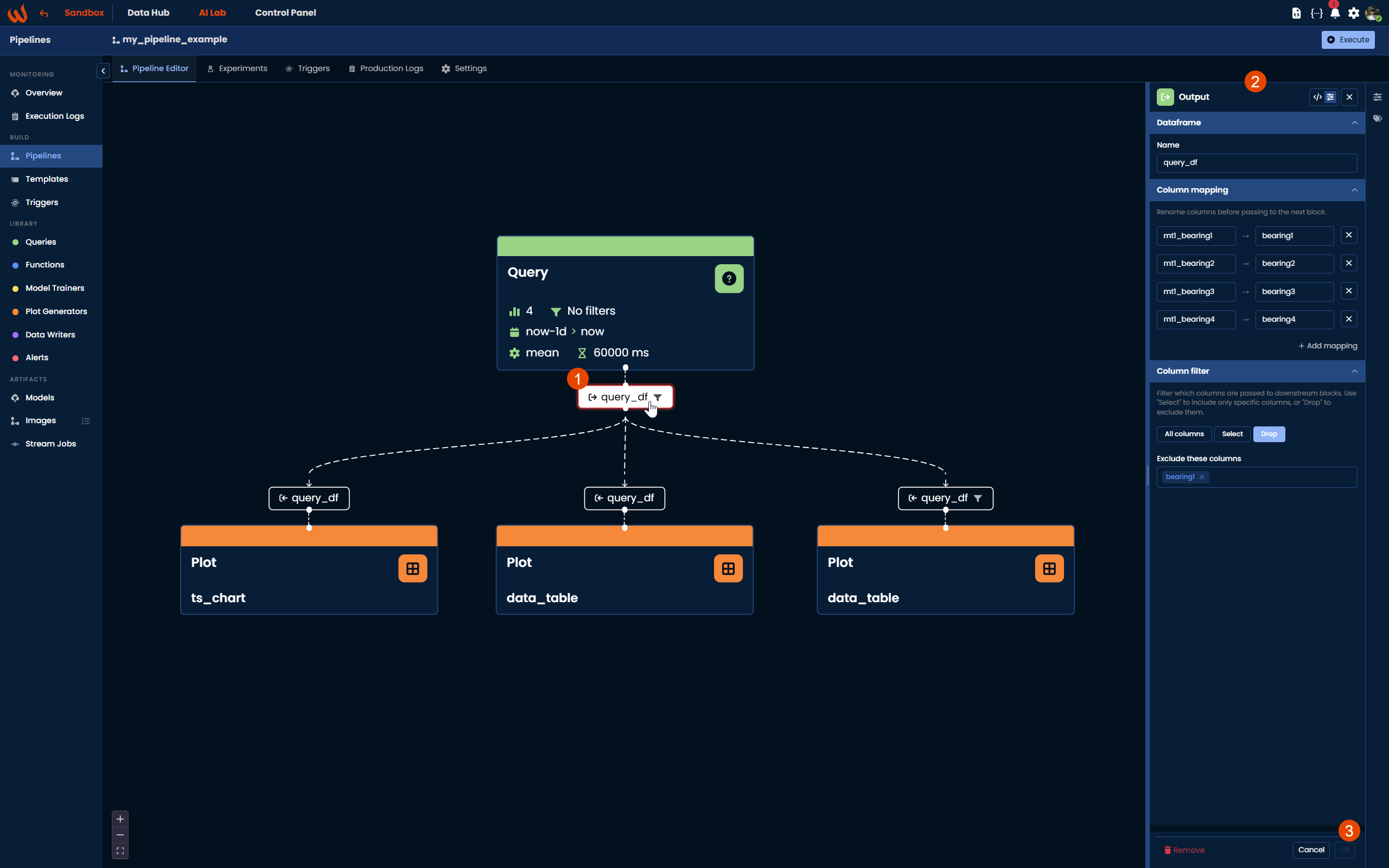
Once the Query step runs, it produces a dataframe named after the df_name parameter. This dataframe contains one column per requested datapoint and one row per aggregation interval within the specified timeframe. It is then passed to the next step in the pipeline via a named output block.
Configuring the Output Block
When working in the Pipeline UI, you can click on the output block to open its configuration panel. This gives you two additional options to control how the dataframe is passed to the next step.
Column Mapping
Column mapping allows you to rename columns before they are passed to the downstream block. This is useful when the column names produced by the query do not match what the next step expects. For example, if your query returns mt1_bearing1 but your preprocessing script expects Bearing1, you can define the mapping here without modifying the script itself.
Each mapping entry follows the format source column → target column. You can add as many mappings as needed using the + Add mapping button.
Column Filter
Column filter allows you to control which columns are passed to the next block. There are three modes:
- All columns (default): all columns from the dataframe are passed through.
- Select: only the columns you specify are passed through, dropping the rest.
- Drop: all columns are passed through except the ones you specify.
This is useful when your query returns more columns than the next step needs, helping you keep the dataframe clean and avoid processing unnecessary data.
Updated 2 months ago