Uploading a Manually Trained Model
Upload a machine learning model developed and trained manually outside the app
Uploading a manually trained model is useful when a solution has been developed outside the Wizata platform. For example in a notebook, a local Python environment, or an external ML workflow.
When to use manual model upload
When to use manual model upload:
- Migrating an existing AI/ML solution into Wizata
- Exploratory research and rapid prototyping, when the final architecture is not yet defined
- One-off training workflows that do not require automation
- External training environments (GPU servers, cloud notebooks, AutoML services)
When NOT to use manual upload
If your ML workflow must support automation, retraining, scaling across multiple assets, scheduled executions or drift-based logic, then using a Wizata Training Pipeline is strongly recommended. Pipelines make training reproducible, traceable, and fully automatable, which essential for industrial MLOps.
Before You Begin
Make sure you have read Understanding Model Storage and Metadata in Wizata
This explains the meaning of:
• Key
• Twin (Asset)
• Property (Condition, recipe, product type…)
• Alias (auto-generated version name)
Understanding these concepts will help you correctly structure your manually uploaded model.
Uploading a Model Manually (UI)
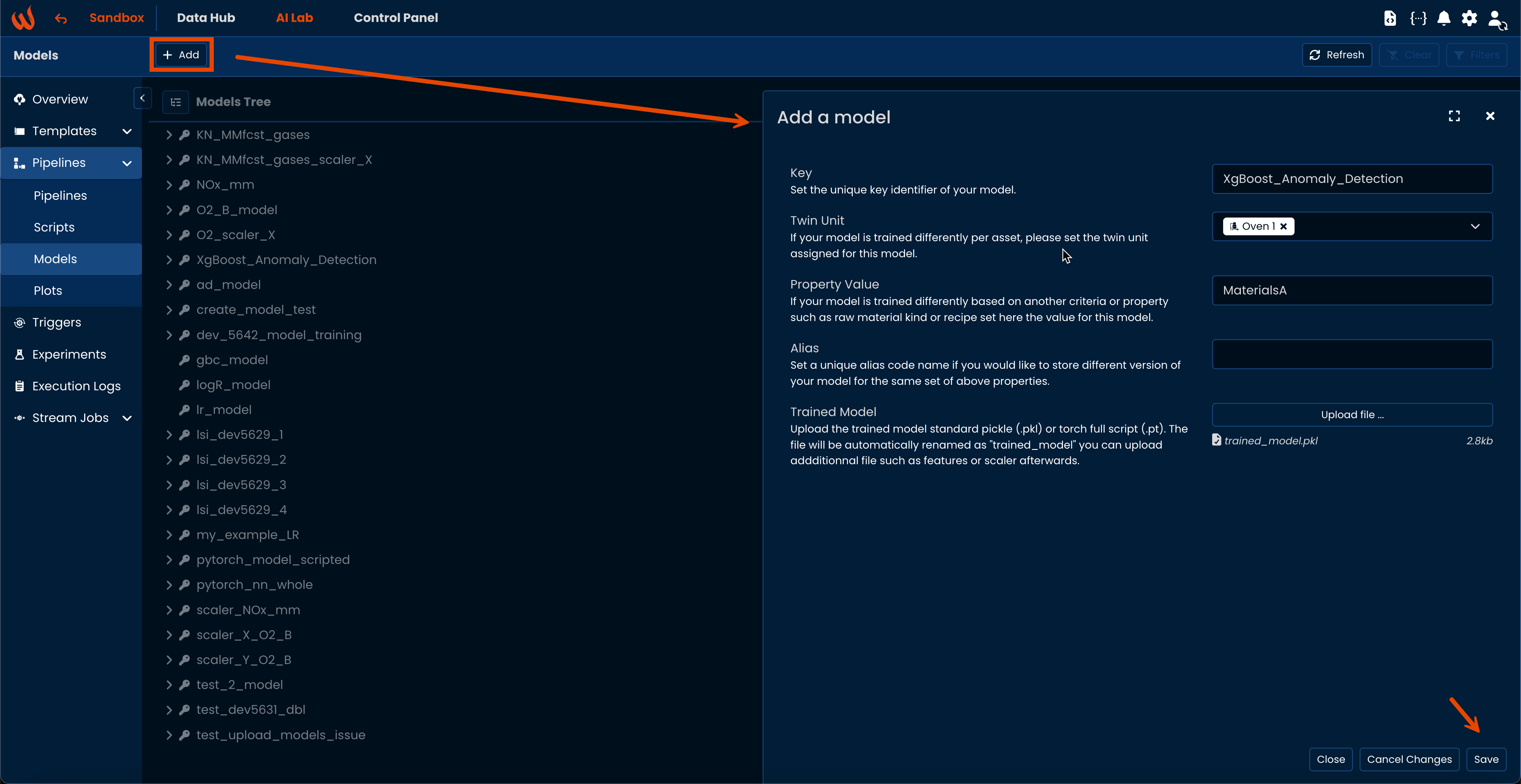
To upload a model through the UI, navigate to AI Lab > Pipelines > Models and then click on "+Add" model.
Fill up the form accordingly with key, if necessary specify a twin and/or a property. You can leave alias empty to autogenerate one or specify a custom one.
The file must be uploaded and must be a pkl or a pt file.
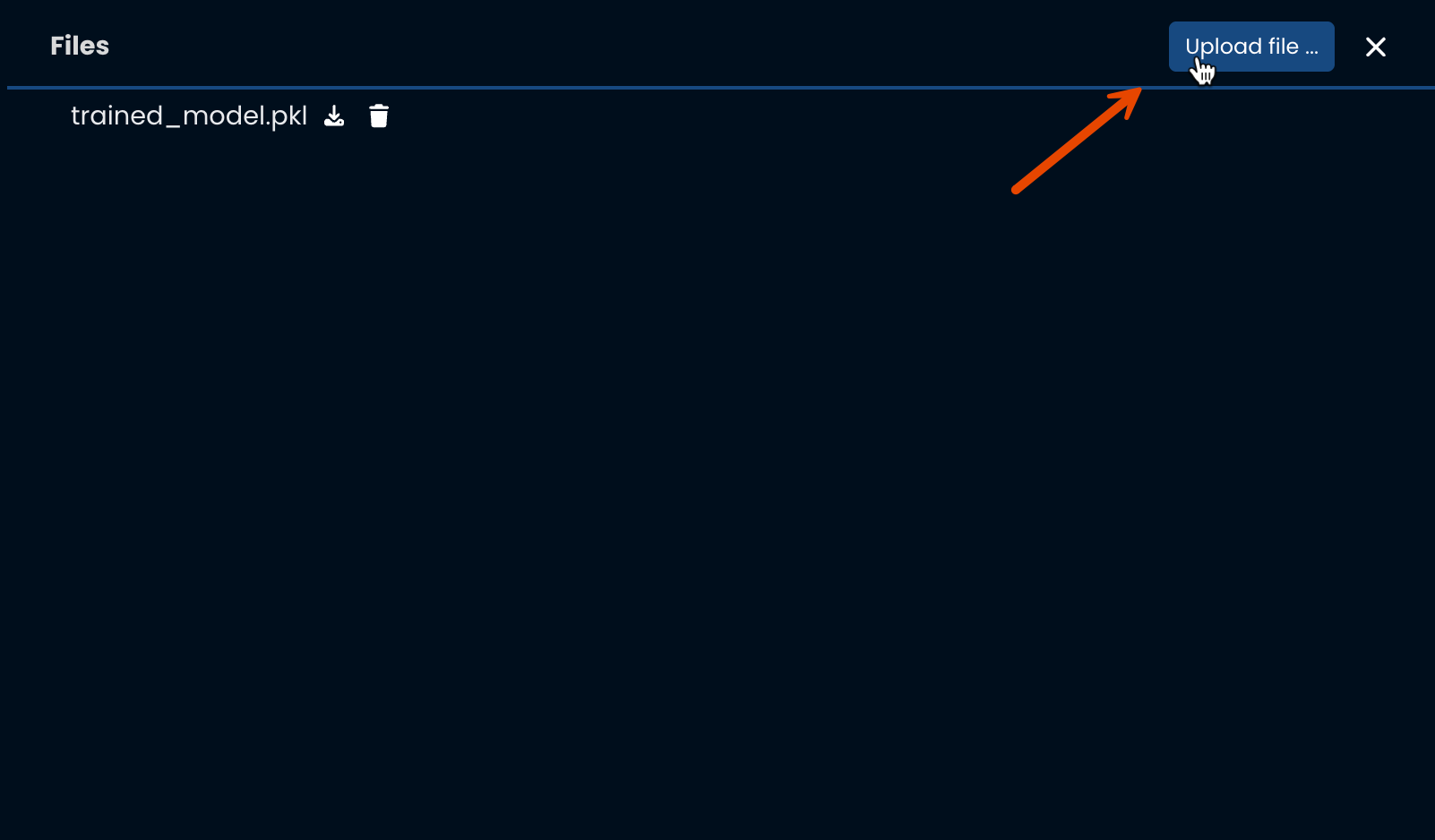
Add Extra Files
You can also through UI, add/remove extra files on your model such as custom JSON, scaler data, reference dataframe, ... anything useful purely informative or to be used during inference.
Uploading a model using the API
The model must be loaded as a Python object, from a pickle or trained within your notebook. As usual you can found all code examples on our git repository.
df = wizata_dsapi.api().query(
datapoints=["mt1_bearing1", "mt1_bearing2", "mt1_bearing3", "mt1_bearing4"],
agg_method="mean",
interval=300000,
start="now-1d",
end="now"
)
x = df[['mt1_bearing1', 'mt1_bearing2','mt1_bearing3']]
y = df['mt1_bearing4']
my_model = LinearRegression()
my_model.fit(x, y)Upload a Model
Therefore you can upload your model using the API.
model_info = wizata_dsapi.api().upload_model(
model_info=wizata_dsapi.ModelInfo(
key="models-01-sample-docs",
twin_hardware_id="mef_plant_a",
trained_model=my_model,
)
)
print(model_info.identifier(include_alias=True))
# > models-01-sample-docs.mef_plant_a@251125_lemon_raccoon_202Make sure you specify all the relevant properties. It is useful to print or store the model identifier with the include_alias to ensure your can find it back.
| Property | Type | Description |
|---|---|---|
| key | str | (required) The key is the base name of the model, typically describing its purpose or algorithm |
| twin_hardware_id | str | The Twins represents the asset the model is associated with and its identified from the twin hardware_id. |
| property_value | str | The value of the property. A property is a variable used inside a Pipeline to contextualize the model. Again platforms can store different train models per property. |
| alias | str | The alias uniquely identifies a specific version of the model. It is automatically generated every time a model is saved, uploaded, or retrained but a custom one can be specified. If using an already existing one, model will erase existing version. |
| file_format | str | By default, "pkl" for pickle but accepts also "pt" for torch scripted model on python version 3.11 and above. |
| source | str | By default, "wizata" to store the model on Wizata app but accepts also "mlflow" if ML Flow is configured. |
Upload a model from a pickle or pt
Make sure when uploading a model from a file that you unpickle the model before passing it as trained_model to Wizata or pass it as bytes_content.
with open("model.pkl", "rb") as f:
my_model = pickle.load(f)
model_info = wizata_dsapi.api().upload_model(
model_info=wizata_dsapi.ModelInfo(
key="models-01-sample-docs-pickle",
twin_hardware_id="mef_plant_a",
trained_model=my_model,
)
)
print(model_info.identifier(include_alias=True)) with open("model.pkl", "rb") as f:
my_model_bytes = f.read()
model_info = wizata_dsapi.api().upload_model(
model_info=wizata_dsapi.ModelInfo(
key="models-01-sample-docs-pickle",
twin_hardware_id="mef_plant_a",
),
bytes_content=my_model_bytes
)
print(model_info.identifier(include_alias=True))Upload extra files
To upload additional files on the model you can use the following logic. The method accepts content as a bytes array. You can pass the file as a path str or directly as a ModelFile. The model can be identified directly as a ModelInfo or using the complete identifier.
features = ["mt1_bearing1", "mt1_bearing2", "mt1_bearing3", "mt1_bearing4"]
features_json = json.dumps(features).encode("utf-8")
wizata_dsapi.api().upload_file(
identifier="models-01-sample-docs.mef_plant_a@251125_lemon_raccoon_202",
path="features.json",
content=features_json
)The model and its extra files are now available on the app through AI Lab > Pipelines > Models
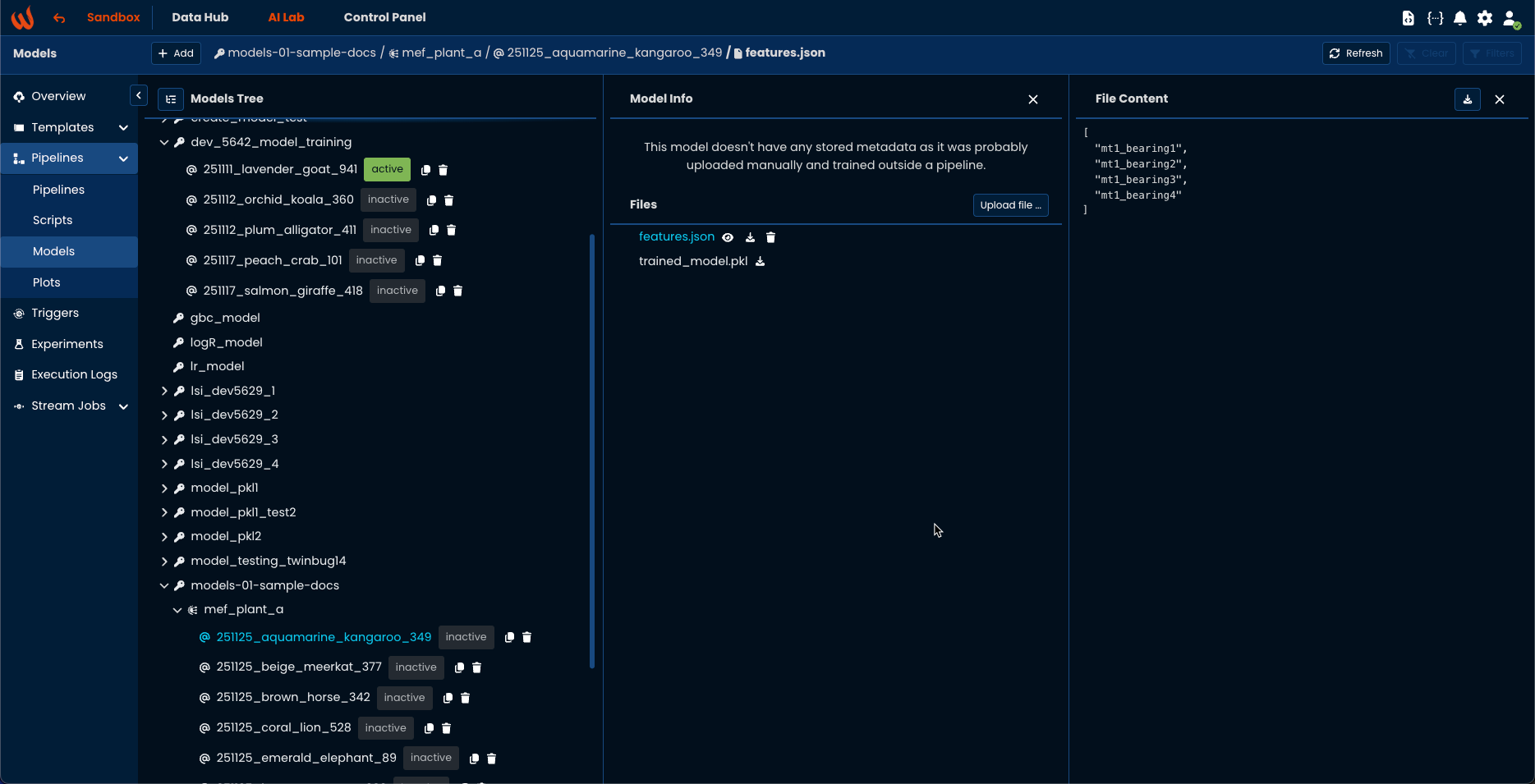
Download your model
You can therefore now either using the model for inference in a pipeline with a model step or test your model locally by downloading it simply through the API.
model_info = wizata_dsapi.api().download_model(
identifier="models-01-sample-docs.mef_plant_a@251125_lemon_raccoon_202"
)
print(type(model_info.trained_model))
# > <class 'sklearn.linear_model._base.LinearRegression'>Download your extra files
Same for upload_file you can use the model_info, file combination or directly the identifier and the path.
model_info = wizata_dsapi.api().download_model(
identifier="models-01-sample-docs.mef_plant_a@251125_lemon_raccoon_202"
)
for file in model_info.files:
if file.path == "features.json":
content = wizata_dsapi.api().download_file(model=model_info, file=file)
features = json.loads(content)
print(features)
# > ['mt1_bearing1', 'mt1_bearing2', 'mt1_bearing3', 'mt1_bearing4']Updated 6 months ago